这篇是 defi-position-reader 系列的第二篇,继续从框架走向真实协议接入。项目代码放在 yulai-123/defi-position-reader。
背景
在上一篇文章中,我们已经搭建了一个通用的 DeFi 协议资产读取框架。这个框架把协议接入拆成两类任务:一类是通过 MetadataSyncer 同步协议公共数据,另一类是通过 Fetcher 读取用户相关的链上状态,并最终输出统一的 Position 数据。
这一篇文章继续沿着这个框架,接入一个真实协议:Aave V3。
Aave V3 是 EVM 生态里非常典型的借贷协议。用户可以向协议供应资产,也可以在抵押约束下借入资产。对资产读取系统来说,它很适合作为第一个真实接入案例,因为它同时覆盖了几类常见问题:市场配置、凭证代币、债务凭证、风险参数,以及基于凭证代币再封装出来的收益类资产。
本文关注的是资产读取与解析,而不是实现借贷交易本身。我们希望回答的是:用户在 Aave V3 中有哪些供应资产、有哪些债务、这些资产属于哪个市场、底层资产是什么,以及这个过程如何映射到项目的 Adapter 架构中。
目标
这次接入的目标可以分成三个层次。
- 理解 Aave V3 的资产模型:Market、Pool、Reserve、aToken、debt token、Yield wrapper 分别是什么。
- 将 Aave V3 映射到项目架构:哪些数据应该由
sync-metadata维护,哪些数据应该在positions查询时实时读取。 - 实现可展示、可调试的资产读取链路:使用 Multicall3 批量调用,通过 CLI 展示用户资产和底层调用过程。
Aave V3 adapter 当前支持 Ethereum、Arbitrum One 和 Base 三条链。策略上分阶段接入:第一阶段支持 Lending,第二阶段支持 StataToken / static aToken 这类 Yield wrapper。Aave 的 Safety Module、Umbrella 或 staked AAVE 更接近 Aave 生态的边界资产,不属于 Aave V3 借贷市场的核心读取链路,因此暂不作为当前接入重点。
正文会先用两张更聚焦的小图说明协议模型和计算链路,完整接入流程图放在文末作为补充。
过程
Aave V3 的资产模型
接入 Aave V3 时,最容易混淆的是 Market、Pool 和 Reserve。
Market 可以理解为一套相对独立的 Aave V3 部署。每个 Market 有自己的核心合约、资产列表和风险参数。例如 Ethereum 上可以同时存在 Core、Lido、EtherFi、Horizon 等不同 Market;Arbitrum One 和 Base 上也各自有自己的 Core Market。
Pool 不是“某一个代币池”。在一个 Market 中,通常会有一个核心 Pool 合约统一处理这个 Market 下的 supply、borrow、repay、withdraw 等用户操作。也就是说,Pool 更像这个 Market 的核心入口,而不是某个资产自己的池子。
Reserve 才是某个具体底层资产对应的储备市场。例如 USDC Reserve、WETH Reserve、wstETH Reserve。每个 Reserve 都有自己的供应量、债务量、aToken、债务凭证和风险参数。
它们之间的关系可以简化成下面这张图。
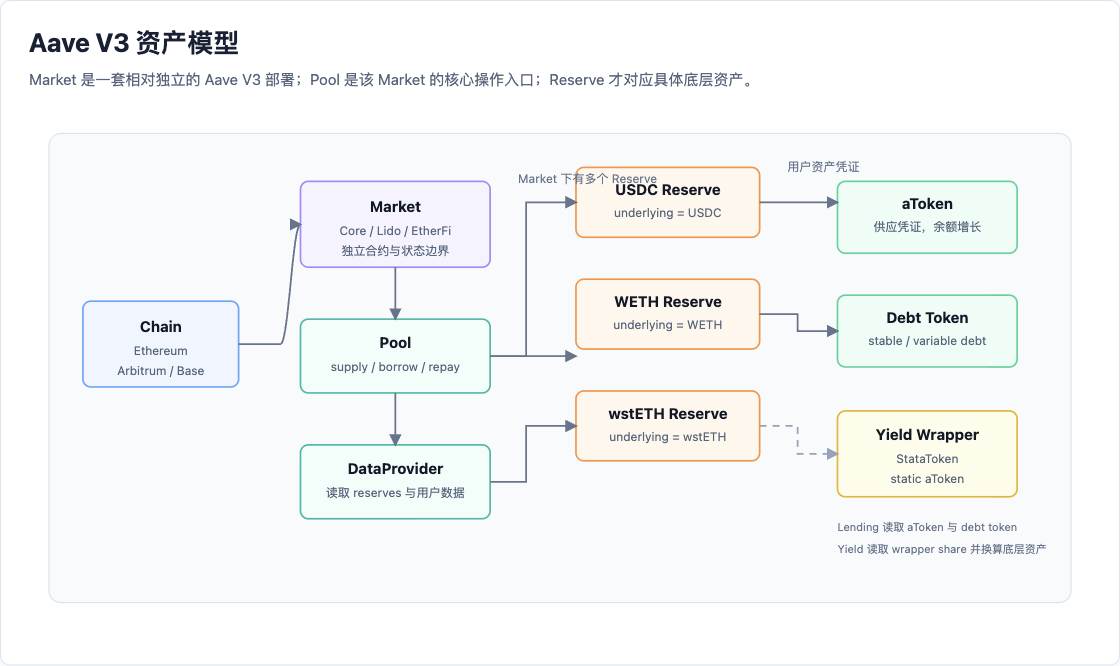
图 1:Aave V3 中 Chain、Market、Pool、Reserve 与用户资产凭证的关系。
从资产读取角度看,Aave V3 的层级关系可以概括为:
1 | Chain |
不同 Market 底层使用不同的合约和状态存储,因此用户仓位在链上是按 Market 隔离记录的。某个 Market 的 Reserve 出现风险事件,不会直接改写另一个 Market 的资产状态。不过在真实风险分析里,不同 Market 仍可能共享治理、预言机资产、外部流动性或同类抵押资产,所以“合约状态隔离”和“经济风险完全无关”不能简单画等号。
Lending:最核心的用户仓位
Aave V3 最核心的资产策略是 Lending。用户供应资产时,协议会给用户一份供应凭证;用户借入资产时,协议会记录对应的债务凭证。
供应侧的凭证是 aToken。比如用户向某个 Reserve 供应 USDC,会得到对应的 aUSDC。aToken 是一种会自动累积收益的凭证,当前余额已经包含了随时间累积的供应收益。因此读取用户供应仓位时,不需要从历史交易里重新计算利息,可以直接读取当前的 currentATokenBalance。
债务侧有 stable debt token 和 variable debt token。用户借款后,债务余额会随着对应利率累积。读取债务时,我们关心的是当前稳定债务和当前浮动债务,而不是最初借了多少。因此代码里会读取 currentStableDebt 和 currentVariableDebt,再合并成该资产的当前债务。
在统一的 Position 模型中,Lending 仓位会被拆成三类资产:
| Position 字段 | Aave V3 中的含义 |
|---|---|
Shares |
用户持有的凭证资产,例如 aToken |
Underlying |
凭证当前对应的底层供应资产 |
Debt |
用户当前借入资产形成的底层债务 |
除了每个 Reserve 的用户数据,Fetcher 还会调用 Pool.getUserAccountData,读取账户级风险指标,例如总抵押、总债务、可借额度、LTV、清算阈值和健康因子 healthFactor。这些数据不是单个资产余额,但对展示用户借贷风险非常重要。
Yield:基于 aToken 的再封装
Yield 这类仓位不是 Aave App 里最常见的用户入口。普通用户在 Aave 页面上主要看到的是 supply 和 borrow;Yield wrapper 更像是给外部协议或高级场景使用的一层封装。
典型例子是 StataToken 或 legacy static aToken。aToken 的余额会随着时间增长,这对某些外部协议并不方便,因为用户持有的份额本身在变化。static aToken 的思路是把“余额增长”的 aToken 包装成“份额固定、份额价值增长”的形式:用户持有的 wrapper share 数量可以不变,但每个 share 能赎回的底层资产会随时间增加。
所以 Yield 的读取逻辑和 Lending 不一样:
1 | 用户持有多少 wrapper share |
如果 vault 暴露 reward token,Fetcher 还会读取可领取奖励并放入 Extra.claimableRewards。这也是为什么 Yield 可以作为第二阶段接入:它依赖的底层资产和 aToken 都来自 Aave V3 Reserve,只是用户持有的是再封装后的 vault share。
如何映射到项目架构
理解协议模型后,接入工作就可以拆成两部分:公共数据同步和用户资产读取。
公共数据不依赖具体用户,例如当前链上有哪些 Market、每个 Market 有哪些 Reserve、每个 Reserve 的 aToken 和 debt token 是什么、是否支持 Yield wrapper。这些数据适合由 sync-metadata 维护,并写入 SQLite cache。
用户数据则必须按地址实时读取,例如用户在某个 Reserve 中有多少 aToken、多少 stable debt、多少 variable debt,或者持有多少 wrapper share。这些数据适合由 positions 命令触发 Fetcher 读取。
Aave V3 当前维护三类 metadata namespace:
| Namespace | 作用 | 数据来源 |
|---|---|---|
markets |
保存当前链支持的 Aave V3 Market 入口合约 | 本地 market config |
lending-reserves |
保存每个 Reserve 的 underlying、aToken、debt token 和风险配置 | DataProvider.getAllReservesTokens 等链上调用 |
yield-vaults |
保存 StataToken / static aToken wrapper 信息 | StataToken factory / legacy static factory |
Fetcher 运行前会先检查这些 metadata 是否存在,并且默认要求它们在 24 小时内更新过。如果 metadata 缺失或过期,Fetcher 会直接报错并提示先运行:
1 | dpr sync-metadata -chain <chain> -protocol aave-v3 |
这个策略看起来严格,但对资产展示更安全。因为如果 metadata 不完整,Fetcher 可能根本不知道某个 Market 或 Reserve 的存在,最终导致用户误以为自己没有资产。相比静默漏资产,直接报错更容易被发现和修复。
用户资产如何计算
Aave V3 的 Position 计算链路可以概括成下面这张图。
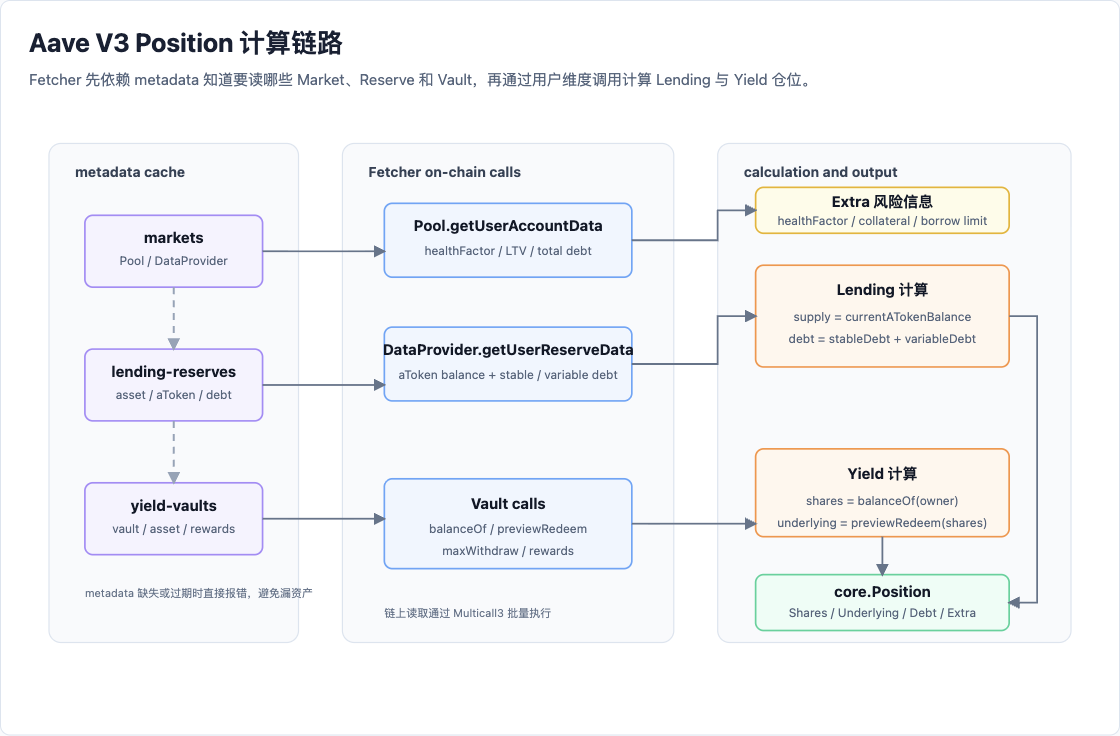
图 2:Fetcher 如何依赖 metadata 读取用户状态,并计算 Lending 与 Yield Position。
Lending 仓位按 Market 读取。每个 Market 会先调用 Pool.getUserAccountData(owner) 获取账户级风险数据,再对该 Market 下的每个 Reserve 调用 DataProvider.getUserReserveData(asset, owner) 获取用户的供应和债务数据。
计算规则可以简化为:
1 | supply = currentATokenBalance |
如果某个 Reserve 的 supply 和 debt 都为 0,就不生成该 Reserve 对应的资产明细。如果一个 Market 下存在任意非零供应或债务,就组合成一个 Lending Position。
Yield 仓位按 vault 读取。Fetcher 先调用 balanceOf(owner) 判断用户是否持有 wrapper share。只有 share 非零时,才继续调用 previewRedeem(shares)、maxWithdraw(owner)、maxRedeem(owner) 和奖励相关方法。
计算规则可以简化为:
1 | shares = balanceOf(owner) |
最终 Lending 和 Yield 都会收敛到统一的 core.Position。对调用方来说,不需要理解每个协议内部如何记账,只需要消费标准化后的 Shares、Underlying、Debt 和 Extra。
工程取舍
这次接入里有几个比较关键的工程取舍。
第一,链上读取统一走 Multicall3。Aave V3 的 metadata sync 和 position fetch 都会涉及大量合约读取。如果每个方法都单独发一次 RPC 请求,不仅速度慢,也容易触发公共 RPC 或节点服务商的限流。通过 Multicall3,可以把多个只读调用合并到一次 aggregate3 中执行。
第二,Multicall 子调用使用 AllowFailure=false。只要批量调用中的某个子调用失败,本轮读取就整体失败。这和 metadata freshness 的策略是一致的:资产读取宁可明确失败,也不要返回一个可能漏资产的结果。
第三,CLI 需要同时支持普通结果和详细链路。普通模式适合用户快速查看某个地址在 Aave V3 中有哪些资产;详细模式适合开发者观察 metadata discovery、缓存校验、合约调用和 Position 组装过程。对于协议接入来说,这类链路展示能显著降低调试成本。
当前支持范围
当前 Aave V3 adapter 的支持范围如下:
| 项目 | 当前状态 |
|---|---|
| Protocol ID | aave-v3 |
| Chains | Ethereum、Arbitrum One、Base |
| Lending | 已支持 |
| Yield | 已支持 StataToken / static aToken wrapper |
| Staked | 暂不接入 |
| Metadata | markets、lending-reserves、yield-vaults |
| 链上读取 | RPC Client + Multicall3 |
代码结构上,Aave V3 的核心文件集中在 protocols/aavev3:
| 文件 | 作用 |
|---|---|
config.go |
Market 配置 |
types.go |
LendingReserve、YieldVault 等 metadata 类型 |
syncer.go |
sync-metadata 逻辑 |
fetcher.go |
用户仓位读取逻辑 |
abi.go |
合约 ABI 与参数编解码 |
这几个文件共同完成了协议接入的闭环:定义市场边界,同步公共数据,读取用户状态,再映射成统一 Position。
运行 Case
为了看到完整效果,可以先选择一条链同步 Aave V3 metadata,再查询某个地址的仓位。下面以 Base 为例,地址可以替换成任意 EVM 地址:
1 | go run ./cmd/dpr sync-metadata \ |
运行时重点看三件事:sync-metadata 的 discovery 阶段是否发现 Reserve / Yield vault,explain 中 metadata cache 是否命中且未过期,positions 是否展示 SUPPLY/SHARES、UNDERLYING、DEBT 和 HEALTH。
如果需要排查某个资产为什么没有展示,可以把 positions 切换成 detail 模式:
1 | go run ./cmd/dpr positions \ |
这会展示更完整的 Position 内容,包括 market、pool、data provider、reserve 明细、vault 信息和 trace 事件。对于真实链上查询,建议配置自有 RPC:
1 | export BASE_RPC_URL=https://your-base-rpc.example |
如果没有配置,项目会使用内置 public RPC fallback;公共节点适合演示,但可能遇到 429、EOF 或响应不稳定。
真实地址的链上资产会随时间变化,如果返回空结果,可以替换成 DeBank 或测试计划中收集到的 Aave V3 持仓地址。
结论
Aave V3 的接入重点不是简单调用几个余额接口,而是先理解协议如何组织资产:Market 是独立部署边界,Pool 是用户操作入口,Reserve 才对应具体底层资产;用户供应资产得到 aToken,借入资产产生 debt token,Yield wrapper 又在 aToken 之上做了一层份额封装。
映射到项目架构后,sync-metadata 负责维护 Market、Reserve 和 Yield vault 这些公共数据,Fetcher 负责读取用户维度的 supply、debt 和 wrapper share,并最终转换成统一的 Position。
这套方法也可以复用到后续协议接入中:先找到协议如何记录用户份额,再找到份额与底层资产的换算关系,最后把公共配置、用户状态和计算过程稳定地展示出来。
附录:完整接入流程图
前面的两张图分别解释协议模型和计算链路。把它们放回项目运行流程中,可以得到完整的 Aave V3 接入链路:
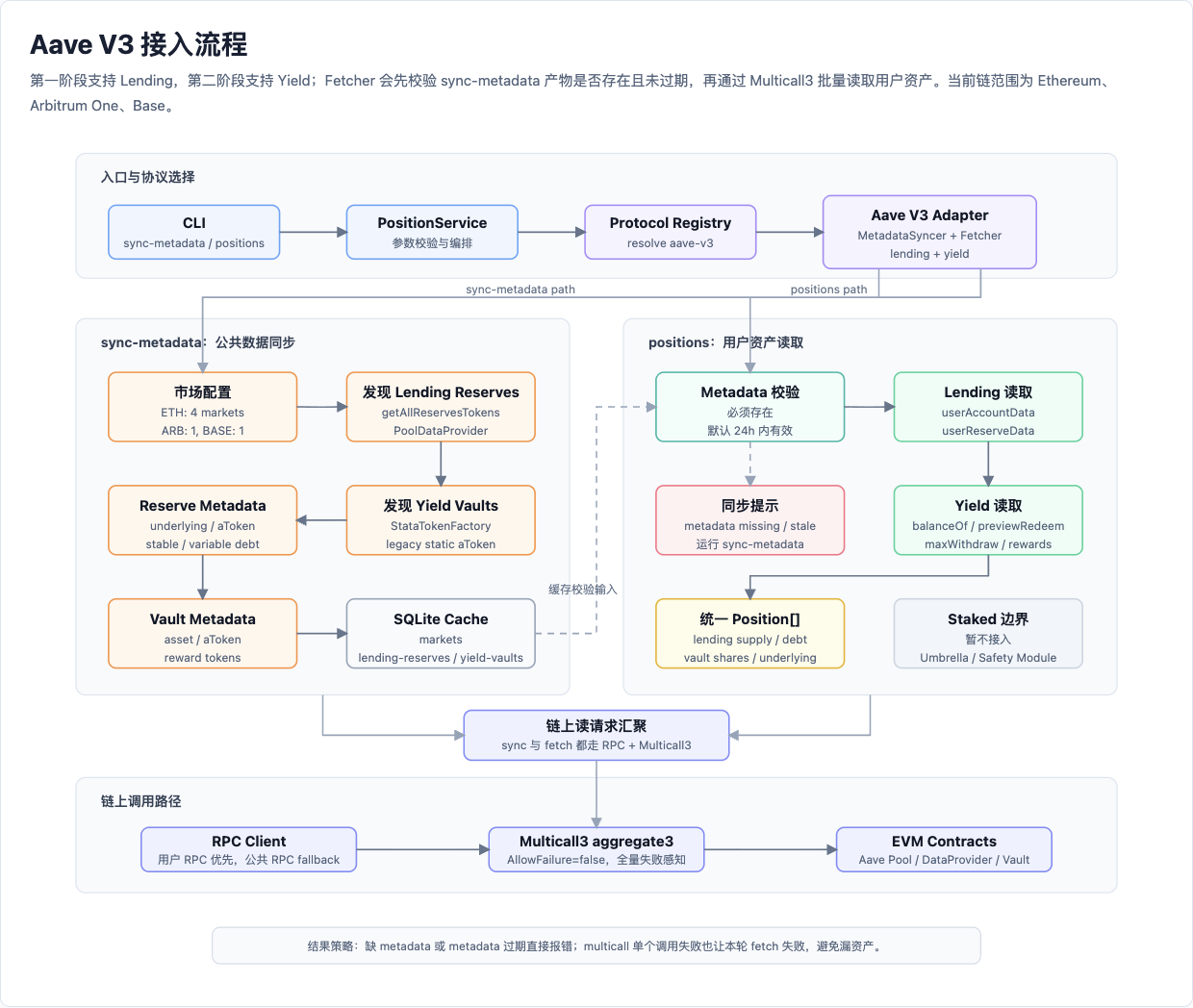
图 3:Aave V3 从 CLI 入口、metadata 同步、用户仓位读取到 Multicall3 链上调用的完整链路。