这篇是 defi-position-reader 系列的第一篇,先写框架和问题边界。项目代码放在 yulai-123/defi-position-reader,后续会按协议逐步补充接入文章。
背景
DeFi 资产并不总是直接表现为钱包里的 ERC20 或 NFT。很多时候,用户持有的是某个协议里的仓位,例如 LP 份额、Vault Share、借贷凭证、质押记录、待赎回资产或债务。用户真正关心的往往不是这些中间凭证本身,而是它们最终对应多少底层 Token。
因此,DeFi 资产读取不能只停留在查询钱包余额这一层,还需要理解协议如何记录用户仓位,并把这些仓位尽量解析成统一、可展示、可追踪的数据结构。
本文会基于一个轻量级 Go 项目,介绍如何在 EVM 生态下组织这类 DeFi 协议资产的抓取与解析流程。
目标
这个项目的目标不是做一个完整的商业级资产索引器,而是搭建一个轻量、可运行、便于扩展的 EVM DeFi 资产读取框架,用来逐步接入不同协议,并展示每个协议资产从链上状态到最终底层 Token 的解析链路。
具体来说,希望实现:
- 定义统一的 Position 数据模型,用来描述用户在协议中的份额、底层资产和债务。
- 拆分协议公共数据同步和用户资产读取逻辑,让每个协议可以独立实现自己的 Adapter。
- 提供 CLI、缓存和协议注册机制,跑通从 metadata 同步到用户 Position 输出的完整流程。
- 为资产穿透链路展示预留空间,例如在 CLI 中展示某个 Position 是如何从凭证、池子状态或协议配置一步步计算出来的。
资产分类与问题边界
从资产读取的角度看,链上资产大致可以分为钱包资产和协议资产。
钱包资产比较直接,例如原生币余额、ERC20 余额、NFT 持仓等,通常可以通过 RPC 节点、索引服务或第三方 API 查询到。协议资产则更复杂,它表示用户在某个 DeFi 协议中的仓位状态,例如质押份额、LP 仓位、借贷资产、债务、待领取收益或赎回请求。
协议资产难读的原因在于,不同协议并没有统一的仓位表达方式。一个协议可能通过 ERC20 凭证表示份额,另一个协议可能通过 NFT 记录仓位,也有一些状态只存在于合约内部的 mapping、队列或结构体中。因此,读取协议资产时通常需要理解协议背景、合约结构、仓位记录方式,以及凭证与底层资产之间的换算关系。
本文关注的是 EVM 生态下的协议资产读取链路:如何获取协议公共数据,如何读取用户仓位,如何把仓位解析成统一的 Position,以及如何为后续展示完整穿透过程打基础。
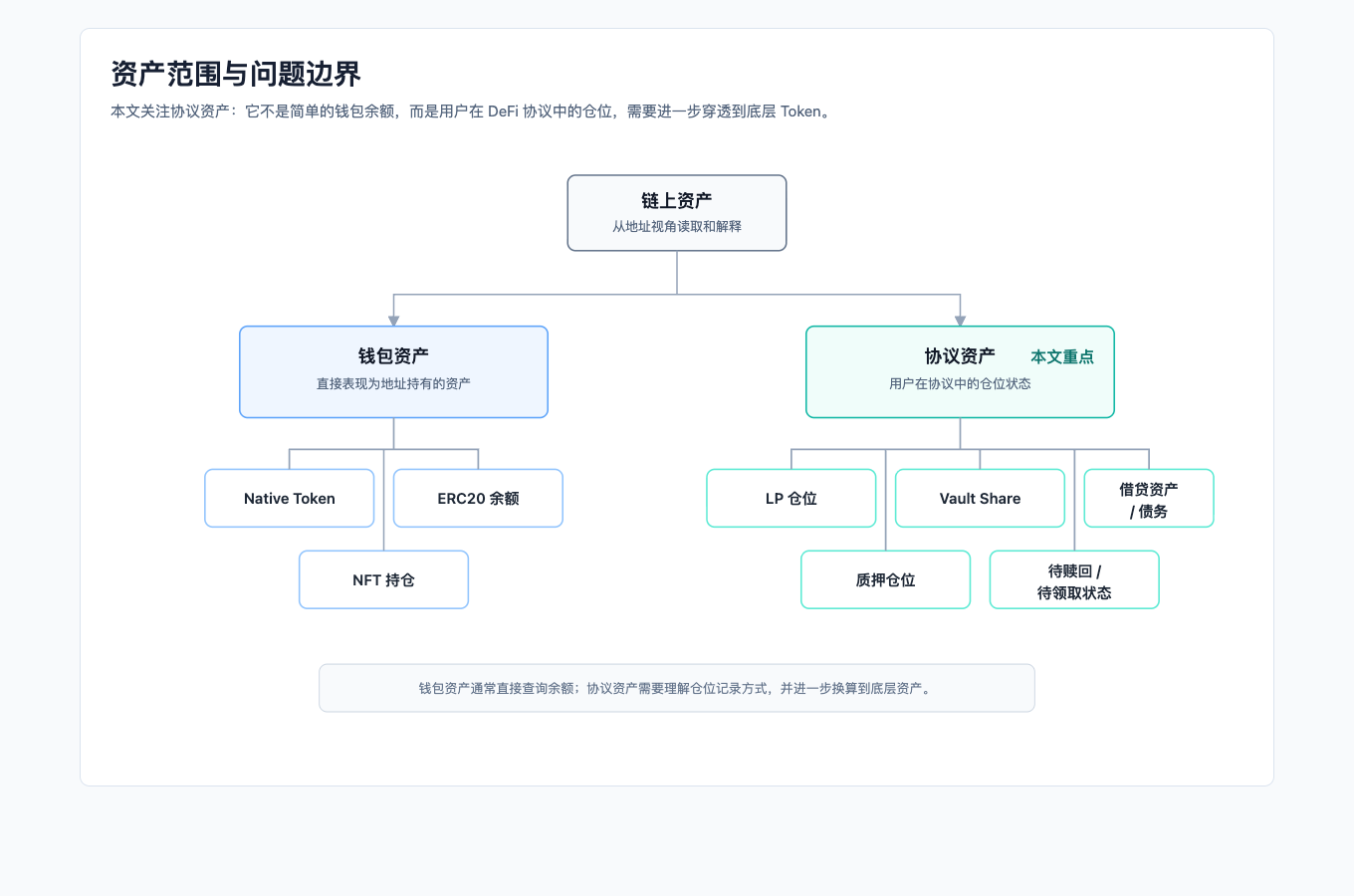
图 1:从钱包资产到协议资产,defi-position-reader 主要关注协议仓位如何穿透到底层 Token。
协议资产读取的方式
读取协议资产,本质上是在回答两个问题:用户的仓位记录在哪里?这份仓位如何换算成底层资产?
常见的仓位表达方式有两类。
凭证型仓位
协议会给用户一个 ERC20、NFT 或类似凭证,用来代表用户在协议中的份额,例如 LP Token、Vault Share、借贷凭证等。
读取这类资产时,通常分两步:先查询用户持有多少凭证,再根据协议提供的汇率、池子状态或换算方法,将凭证份额换算成底层资产数量。
内部记账型仓位
有些协议不会给用户一个可直接查询的钱包凭证,而是把用户仓位记录在合约内部,例如锁仓、排队赎回、待领取收益等状态。
读取这类资产时,需要调用协议合约提供的用户维度查询方法,或者根据协议内部的队列、状态和计算规则,还原用户当前对应的资产数量。
单个协议的读取流程看起来并不复杂,难点在于不同协议的资产模型差异很大。接入一个新协议时,开发者通常需要快速理解它的业务背景、合约结构、凭证与底层资产的换算关系,以及已有接入是否需要随着协议升级同步调整。
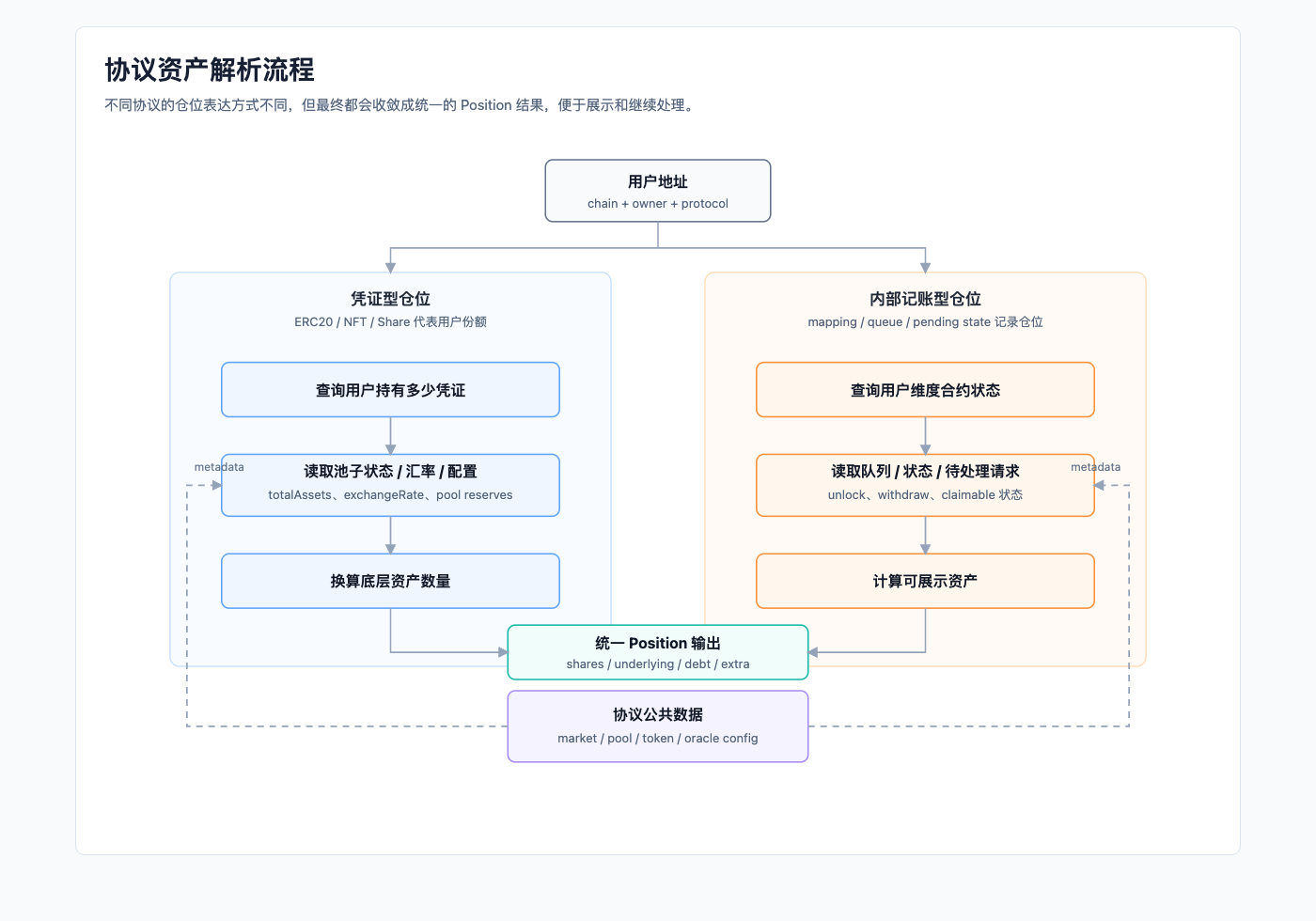
图 2:读取协议资产时,需要把用户仓位记录和协议公共状态一起放进计算链路。
具体架构
从代码运行链路看,项目更适合按四个核心概念理解:CLI、Service、Protocol Registry 与 Adapter、公共模型与缓存层。CLI 提供命令入口;Service 负责应用编排;Protocol Registry 根据 chain 和 protocol 选择需要执行的 Adapter;每个 Adapter 再提供自己的 MetadataSyncer 和 Fetcher;公共模型与缓存层则提供统一数据结构和 metadata 存储能力。
CLI 层是当前项目的命令入口。用户可以通过 CLI 查看支持的链和协议,触发 metadata 同步,也可以查询某个地址在指定协议中的资产结果。
Service 层位于 pkg/service,负责把 Registry、Adapter 和 Metadata Store 串起来。执行 sync-metadata 时,Service 会先通过 Registry 找到目标 Adapter,再调用它的 MetadataSyncer;执行 positions 时,Service 会调用目标 Adapter 的 Fetcher,并对返回的 Position 做必要的补全和排序。
Adapter 是协议接入的边界。它负责声明协议描述信息,并提供对应的 MetadataSyncer 和 Fetcher。
MetadataSyncer 负责同步协议级别的公共数据,例如市场列表、池子配置、底层资产列表、凭证代币信息、利率模型或 oracle 配置等;这些数据通常不直接依赖某个用户地址,但 Fetcher 在解析用户仓位时会用到。
Fetcher 则负责读取用户在协议中的仓位状态,例如凭证代币余额、质押份额、借贷仓位、赎回队列等;随后结合协议规则和必要的 metadata,将这些原始状态解析成统一的 Position 结果,尽量拆分出 shares、underlying、debt 等底层资产信息。
MetadataSyncer 本身不实现定时任务框架,它只提供一次同步逻辑;在实际使用中,可以通过 CLI 手动触发,也可以交给 cron 或外部调度系统周期性执行。当前设计中,Service 会把 Metadata Store 传给 Syncer,是否写入缓存由具体 Syncer 决定;同步后的数据可以供 Fetcher 后续读取,数据新鲜度则取决于外部触发同步的频率。
公共模型与缓存层可以理解为项目的共享基建。代码中的 pkg/core 定义了各层共同使用的数据结构,例如 Chain、Token、TokenAmount、Position、MetadataInfo 和 ProtocolDescriptor;pkg/cache 则提供 Metadata Store,用来缓存协议公共数据。当前项目里 Metadata Store 默认使用 SQLite 实现,后续也可以替换成其它存储。
这种注册式的 Adapter 结构可以让协议接入保持相对独立。接入真实协议时,可以按 protocols/{protocol-id} 目录维护各自的协议描述、metadata 同步和用户仓位读取逻辑。实际业务场景还会多不少细节内容,比如如何维护代币行情、如何对外提供接口服务、如何展示每个资产的穿透计算链路等等。
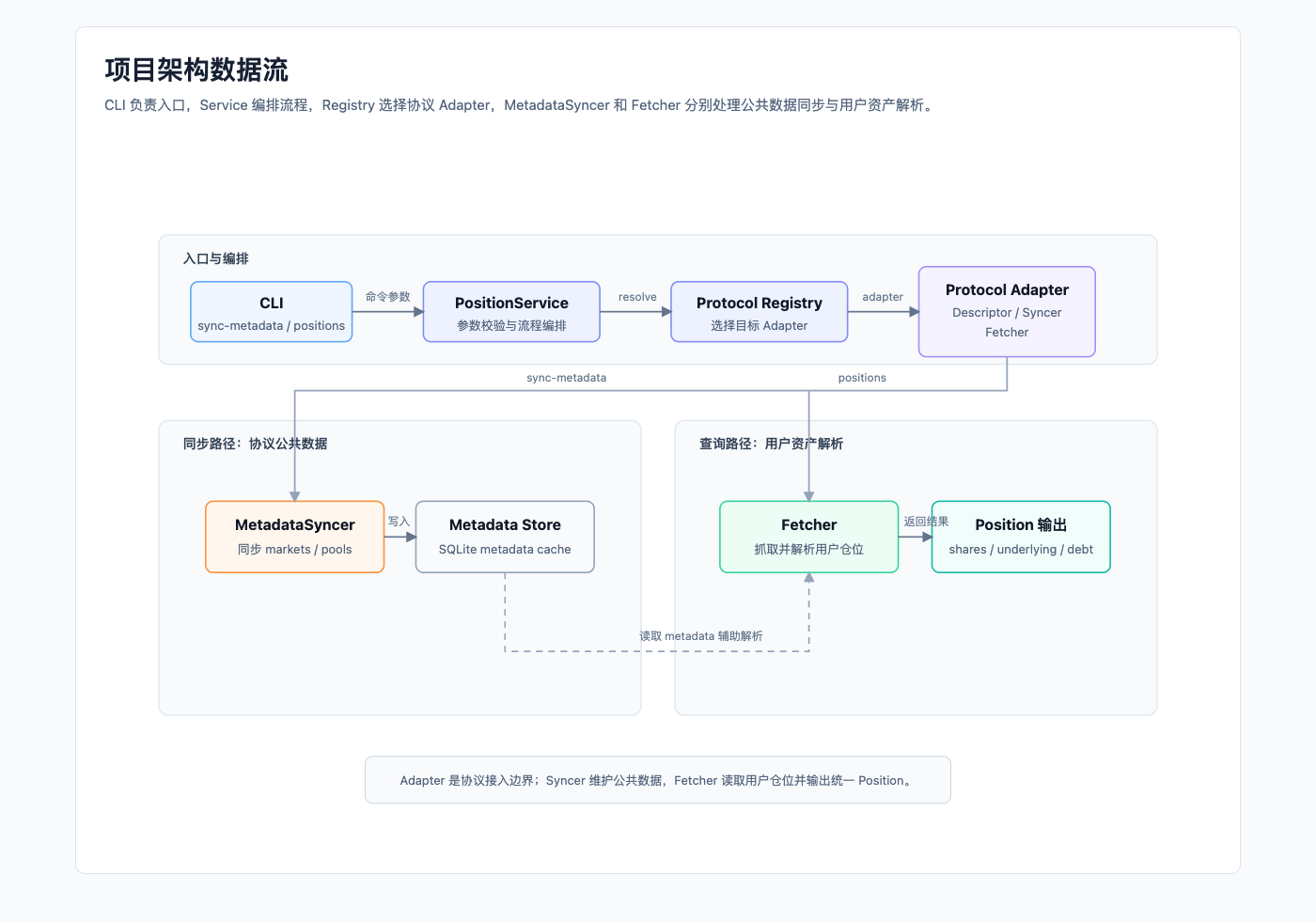
图 3:CLI、Service、Adapter、Fetcher 和 Metadata Store 之间的数据流。
代码结构
当前项目目录保持得比较轻量,核心代码主要分为框架层和协议实现层。
1 | cmd/dpr/ CLI 入口,负责解析命令并调用 service |
协议接入的核心边界定义在 pkg/adapter 中。
1 | type Adapter interface { |
Adapter 负责把一个协议的描述信息、公共数据同步逻辑和用户资产读取逻辑放在同一个边界下。MetadataSyncer 面向协议公共数据,Fetcher 面向单个用户地址的资产读取。
最终输出统一收敛到 Position 模型。
1 | type Position struct { |
这样后续接入真实协议时,每个协议只需要把自己的链上状态映射到统一的 Position 结构中。
和 Position 配套的是 MetadataInfo,它用来描述一份 metadata 的 chainId、protocol、namespace、version、blockNumber、更新时间和数据来源;缓存 key 也按 chainId / protocol / namespace 组织,方便真实协议把 markets、reserves、oracle-config 等公共数据拆开维护。
结语
DeFi 协议资产读取的框架骨架并不复杂:通过 MetadataSyncer 维护协议公共数据,再由 Fetcher 读取用户仓位,并解析成统一的 Position 结果。真正复杂的是不同协议的仓位模型差异,以及从凭证、池子状态、协议配置到最终底层 Token 的穿透计算过程。
这个项目会先保持轻量,重点跑通 EVM 协议资产读取的核心链路。后面会继续按协议写接入文章,从 Aave V3 这类借贷协议开始,再扩展到 Lido、Uniswap V2 / V3、Compound V3 等协议,并逐步把每个资产的解析路径展示出来。